Link Time Optimization 在ARM Compiler 6中优化简介
| 文章来源:完美体育·(中国)手机网页版科技 发布日期:2021.1.19 浏览次数:5570 次 |
Link Time Optimization 在ARM Compiler 6中优化简介
介绍
Link TimeOptimization (LTO) 顾名思义,是在链接程序的时候进行的优化形式。建立单独编译的多个源文件的镜像时,这是特别有用的。编译器不具有跨编译源文件的所有编译单元的完全可视性,因此它会错过了具有的全部代码是一个文件的一部分许多优化的机会。
其他跨过程优化,如多文件编译和全程序优化有助于解决编译单元缺乏可见性,它使编译器能够执行跨文件内联和删除未使用的函数。 然而,LLVM能够执行空闲和运行时优化以及整个程序分析和积极的重组转换。 这个基础架构由LTO利用来实现更高级别的优化,我们将在本文的实现部分看到如何完成。
在我们可以深入了解ARM编译器6中的LTO详细信息之前,请注意,此功能目前仍在开发中,目前处于[ALPHA]级别(参见ARM Compiler 6文档中的“支持级别定义”部分)。 在将来的ARM编译器6版本中,它将是一个完全支持的功能。
Design and Implementation
实现LTO的关键是生成用于描述源代码的中间表示的位代码(也称为字节码)文件。 位代码包含有关源文件的更多信息,而不是ELF对象,使链接器能够生成更优化的文件。
当使用-flto选项调用armclang时,它将为使用此选项编译的每个源文件生成位代码文件,并将其传递给链接器。 链接器然后处理位代码文件以发出可以与库对象链接的优化的ELF对象。
启用LTO时,编译器和链接器执行以下步骤:
1.器将源代码转换成称为位代码的中间代码。 这也包含模块依赖信息。
2.器与其他ELF对象文件一起处理这些位代码文件,并在将它们传递给链接时间优化器(llvm-lto)实用程序之前从中提取模块依赖关系信息。
3.模块的依赖关系信息允许链接时间优化器保留所有必要的模块,并删除其余模块,从而创建高度优化的ELF对象文件。
4.时间优化对象文件与其他ELF对象文件和预编译库链接以生成最终的可执行映像。
5.的依赖关系信息允许链接时间优化器保留所有必要的模块,并删除其余的模块,从而创建高度优化的ELF对象文件。
6链接时间优化对象文件与其他ELF对象文件和预编译库链接以生成最终的可执行映像。
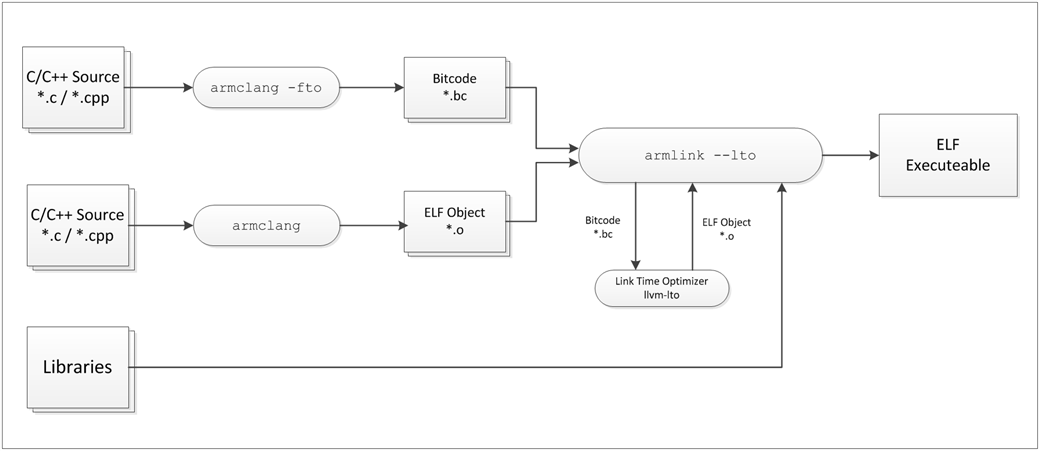
图表 1: 该框图是链接时间优化中涉及的步骤的可视化表示
例程
该示例来自LLVM网站上可用的示例代码。 有关构建过程的其他相关信息如下所示:
•用于构建此示例的编译工具是ARM编译器6.3。
•它是基于64位Windows平台构建的(结果与平台无关)。
•这些示例针对ARMv8-M架构。
查看以下的C文件:
[td]
上面的源代码可以用下面的图表来表示
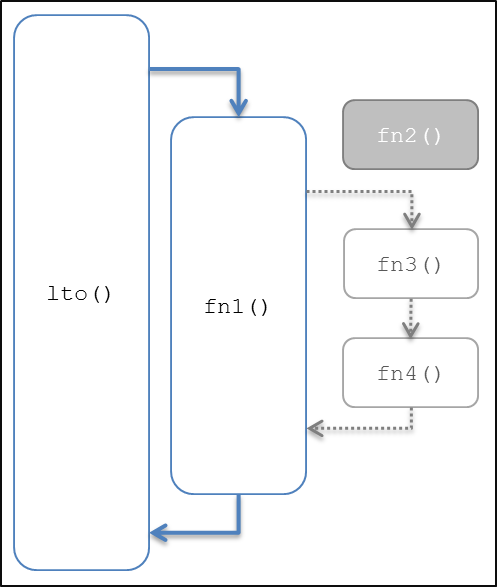
图表 2: 预期程序流
通过分析例程代码,我们可以得出以下结论:
· 函数 fn2() 没有被代码中其他函数调用过。
· 函数fn3() 调用 fn4().
· 函数 fn1() 条件下调用 fn3().
· 函数 lto() 调用 fn1().
· fn3() 只有在i<0的条件被fn1()调用。
· 调用函数fn2() 唯一的方式是使i的值小于0.
· 变量定义为静态的,只能由同一个单元内的函数修改
· 因为fn2()从没有调用, FN3()被执行的条件是永不满足.
· 这意味着fn3() 从没有被fn1()调用.
· 这意味着fn4()将永远不会被调用,因为它需要被fn3()调用。
记住这一点,我们将使用该示例来比较使用和不使用LTO生成的代码,方法如下:
1. 未使用链接时间优化 (using ARM Compiler 6.3)
2. 可选的链路时间优化(using ARM Compiler 6.3)
3. 完整的链路时间优化 (using ARM Compiler 6.3)
4. ARM Compiler 5在所有可用的程序间优化
这将有助于我们更好地了解LTO在ARM编译器6中的实现和益处。在我们向前推进之前,您熟悉一些常用的优化技术和术语reading the knowledge article. 将有益于了解LTO。
Compiling without Link Time Optimization
在此示例中,对于任何源文件,LTO未启用。 这意味着编码器不会生成位代码文件,并且不执行链接优化。 编译器直接生成由armlink链接以生成可执行映像的对象文件。 重要的是要注意,在这种情况下,这两种源文件都是使用-O2编译的,以使比较尽可能接近使用LTO的编译。 启用LTO时,选择的默认优化级别为-O2。
[td]
Generated Assembly code

Optimizations
编译器的–O2 选项执行了以下优化:
数 foo3() 已经变成被函数foo1()调用的内联函数has been inlined into its callerfunction foo1().
· 在lto()使用优化尾部调用foo1()。
使用选择性 Link Time Optimization编译
在这个例子中,两个文件(foo.c)中的一个被编译,启用了LTO。 这意味着只能为foo.c生成位码文件,允许llvm-lto仅在源代码的一部分上应用优化
[td]
Generated Assembly code
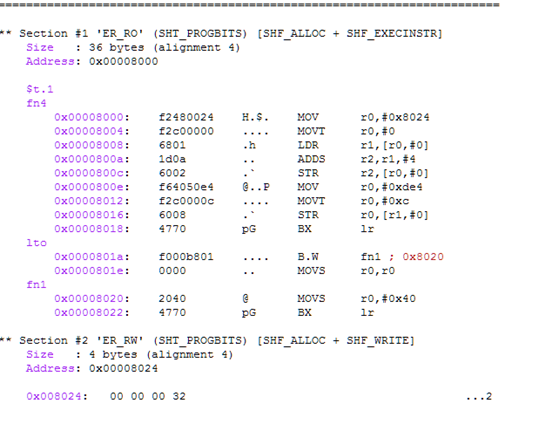
Optimizations
除了通过在优化级别-O2进行编译实现的优化之外,仅在foo.c中启用LTO会导致以下附加优化:
· 编译器移除了 fn2() ,因为他没有被源文件中的其他函数调用.
· llvm-lto 检测到在fn1()中i的值会一直大于0,删除了调用函数fn3().
· 这意味着ret_val1的值没有被fn3()改变,函数fn1()可以优化为只是返回固定值0x40或64.
· 编译器移除了fn3()但是失去了移除fn4()的优化机会,因为他是被移除的函数fn3()所调用,这是因为lto.c 没有在编译时使能LTO选项.
编译时使用Link Time Optimization全功能
在这个例子中所有输入的源文件都使用了LTO编译选项
[td]
Generated Assembly Code

Optimizations
如之前的提出的优化选项(选择性的LTO优化),当ARM编译器6对所有源文件启用LTO时,能够执行额外的过程间优化:
· 函数fn1()嵌入到lto()中,即使在不同的编译单元中定义了fn1()。
· 类似地,编译器可以确定,由于fn3()不会被fn1()调用,它可以删除fn4()的定义(这在fn3()和fn4()被定义在不同的文件中)之前是不可能的。
· 这意味着编译器现在可以将整个源代码减少为单个lto()函数,从而产生如上所示的非常小而高效的代码。
ARM Compiler 5模块间的优化应用
在这一点上,与ARM Compiler 5相比,ARM Compiler 6中的过程间优化的改进是值得比较的。
下面的示例显示了通过使用ARM Compiler 5中可用的所有可用的进程间优化来生成的代码。
[td]
[注意:将基于ARMv7-M的Cortex-M7指定为cpu选项的原因是ARM编译器5不支持ARMv8-M目标]
上述命令需要运行两次。 一旦生成包含功能使用信息的反馈文件。 第二次使用生成的反馈文件来删除基于第一次编译的未使用的功能/部分。
Generated Assembly Code
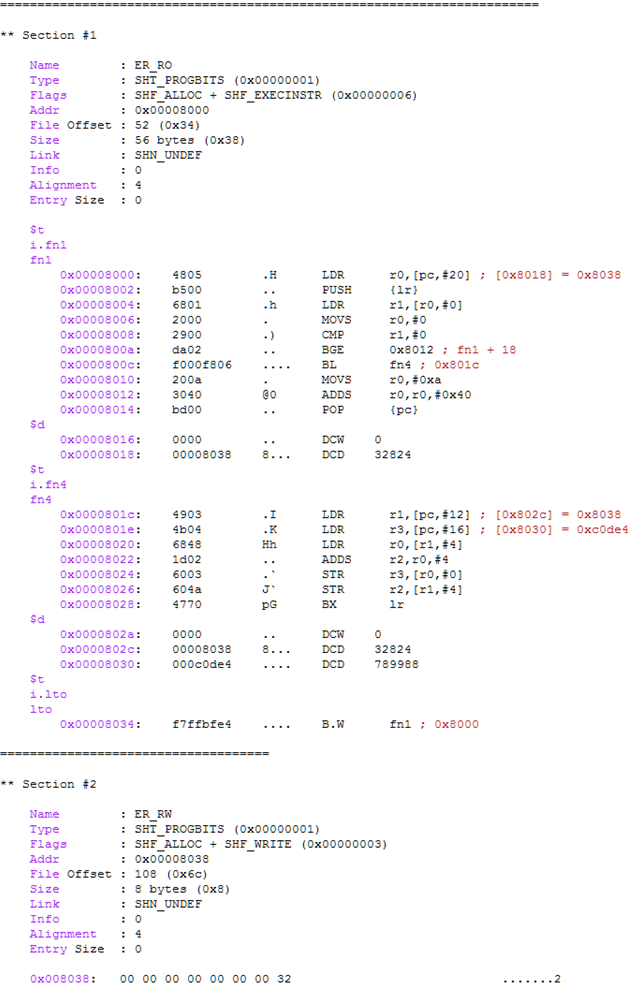
Optimizations:
在本编译中,编译器只能执行以下两个优化:
· 删除未使用的功能fn2()。
· 将fn3()内联到fn1()中。
· 调用函数fn1()的尾调用优化。
在ARM Compiler 6中LTO 现存的限制和局限性
如前所述,LTO目前是[ALPHA]级别,目前对其使用有一些限制和局限性。 ARM编译器6中的armclang编译器使用armlink作为链接过程,因为LLVM Clang没有自己的集成链接器(LLVM clang具有不同的链接器,用于位代码文件的链接器llvm-link和lld链接标准对象文件)。 使用armlink作为链接器可以更容易地链接使用ARM Compiler 5和ARM Compiler 6构建的对象,并且还可以利用armclang带来的所有好处。 目前,如何使用LTO有一些限制,随着工具链的成熟,将会克服。
· 无法对静态库执行LTO,因为armar或armclang无法生成库的位代码文件。
· LTO不支持部分链接,因为它仅适用于elf对象而不是位码文件。
· 如果库代码调用源代码中定义的但由链接时间优化器删除的函数,则可能会导致链接错误。
· 支持LTO对象的分散加载,但建议对不具有严格放置要求的代码和数据。
· Bitcode对象不能保证在编译器版本之间兼容。 这意味着您应该确保在与LTO链接时使用相同版本的编译器构建所有的位代码文件
结论
链接时间优化是一个非常有前景的优化技术,通过在ARM编译器和链接器之间进行更紧密的集成来实现。 它目前有一些限制,将来会被克服,即使在目前的状态下,它非常强大,可以生成针对大小进行高度优化的代码,这也可以提高性能。 此示例显示了LTO可以实现的代码大小和性能的最大优势。 重要的是要记住您可能获得的结果,LTO可能会根据应用的源代码的特性而有所不同。
本文来自完美体育·(中国)手机网页版科技,原文地址:
/customerService/resource-list.asp?id=570,转载请注明出处。
 产品中心
产品中心 服务与支持
服务与支持 关于完美体育·(中国)手机网页版
关于完美体育·(中国)手机网页版 联系我们
联系我们 关注我们
关注我们
手机网页版天猫官方旗舰店")


手机网页版B站帐号")




手机网页版")
